In the latter part of the 2000s, DevOps solutions emerged as a set of practices and solutions that combines development-oriented activities (Dev) with IT operations (Ops) in order to accelerate the development cycle while maintaining efficiency in delivery and predictable, high levels of quality.
Copyright by www.forbes.com
 The core principles of DevOps include an Agile approach to software development, with iterative, continuous, and collaborative cycles, combined with automation and self-service concepts. Best-in-class DevOps tools provide self-service configuration, automated provisioning, continuous build and integration of solutions, automated release management, and incremental testing.
The core principles of DevOps include an Agile approach to software development, with iterative, continuous, and collaborative cycles, combined with automation and self-service concepts. Best-in-class DevOps tools provide self-service configuration, automated provisioning, continuous build and integration of solutions, automated release management, and incremental testing.
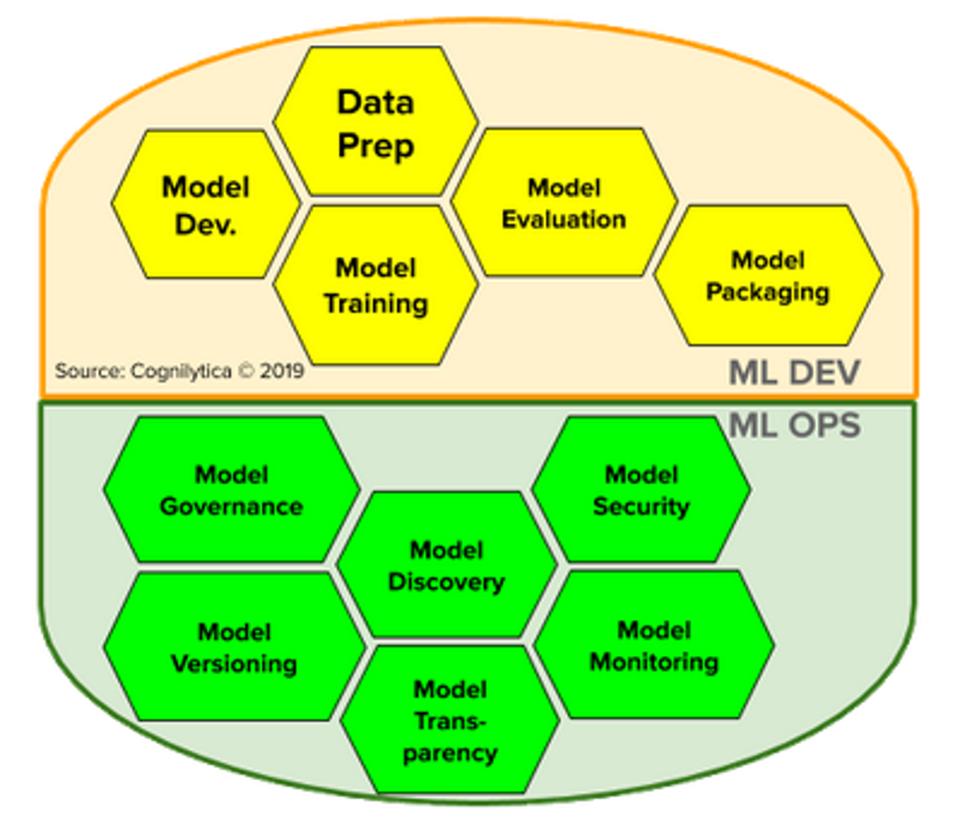
Solutions for DevOps include tools for managing development communication, processes, and tasks, capabilities for testing and integration, ability to provision server, application, and infrastructure, tools for managing code, artifacts, releases, and monitoring of logs and deployments. In this way, organizations can quickly build, develop, test, deploy, and manage code quickly with high degrees of visibility and quality. Given the track record of success that DevOps has had in making application development more robust, efficient, and speedy, it makes sense that developer-focused organizations want to apply DevOps approaches and methodologies to the development, deployment, and management of machine learning models.
Applying DevOps to ML
However, DevOps approaches to machine learning (ML) and AI are limited by the fact that machine learning models differ from traditional application development in many ways. For one, ML models are highly dependent on data: training data, test data, validation data, and of course, the real-world data used in inferencing. Simply building a model and pushing it to operation is not sufficient to guarantee performance. DevOps approaches for ML also treat models as “code” which makes them somewhat blind to issues that are strictly data-based, in particular the management of training data, the need for re-training of models, and concerns of model transparency and explainability.
As organizations move their AI projects out of the lab and into production across multiple business units and functions, the processes by which models are created, operationalized, managed, governed, and versioned need to be made as reliable and predictable as the processes by which traditional application development is managed. In addition, as the markets for AI shift from those relatively few organizations that have the technical expertise required to build models from scratch to those enterprises and organizations looking to consume models built by others, the focus shifts from tooling and platforms focused solely on model development to tools and platforms focused on the overall usage, consumption, and management of models.
Implementing artificial intelligence solutions at scale can be challenging. Many organizations and public sector agencies struggle to rapidly deploy, manage and secure the machine learning models that power the core of today’s AI solutions. Furthermore, data scientists, IT operations, data engineering, line of business, and ML engineering teams often work in silos. This results in complexities for creating, managing, and deploying ML models within their own division or organization. These challenges are further complicated as these organizations share those models within or across the entire organization or agency, or alternatively consume third-party models or models from outside the organization. As a result, the increased complexity of dealing with multiple models in different versions from multiple sources result in issues around model versioning, governance of models and access, potential security risks, challenges with regard to monitoring model usage, and duplicated efforts with multiple teams creating very similar models.
While much of the attention up until now has been focused on the development of machine learning models, as the industry moves from innovators and early adopters to the early majority, later entrants will be more concerned about consuming models developed by others and adoption of recognized best practices rather than building their own models from scratch. This means that these model consumers will be primarily concerned with the quality and reliability of existing models more so than attempting to create a data science organization and investing in tools, technology and people to build their own models.
Thank you for reading this post, don't forget to subscribe to our AI NAVIGATOR!
Simply training machine learning models isn’t sufficient to provide required capabilities. Once a model has been trained, it needs to be applied to a particular problem, but you can apply that model in any of a number of ways. The model can sit on a desktop machine providing results on demand, or it can sit on the edge in a mobile device, or it can sit in a cloud or server environment providing results to a wide range of use cases. Each one of these places where the model is being placed into a real-world situation can be considered a separate deployment, so simply saying the model is deployed doesn’t give us enough information. Putting machine learning models into real-world environments where they are acting on real-world data and providing real-world predictions (i.e. inferencing) is called “operationalizing” the machine learning models. […]
Read more – www.forbes.com









In the latter part of the 2000s, DevOps solutions emerged as a set of practices and solutions that combines development-oriented activities (Dev) with IT operations (Ops) in order to accelerate the development cycle while maintaining efficiency in delivery and predictable, high levels of quality.
Copyright by www.forbes.com
Solutions for DevOps include tools for managing development communication, processes, and tasks, capabilities for testing and integration, ability to provision server, application, and infrastructure, tools for managing code, artifacts, releases, and monitoring of logs and deployments. In this way, organizations can quickly build, develop, test, deploy, and manage code quickly with high degrees of visibility and quality. Given the track record of success that DevOps has had in making application development more robust, efficient, and speedy, it makes sense that developer-focused organizations want to apply DevOps approaches and methodologies to the development, deployment, and management of machine learning models.
Applying DevOps to ML
However, DevOps approaches to machine learning (ML) and AI are limited by the fact that machine learning models differ from traditional application development in many ways. For one, ML models are highly dependent on data: training data, test data, validation data, and of course, the real-world data used in inferencing. Simply building a model and pushing it to operation is not sufficient to guarantee performance. DevOps approaches for ML also treat models as “code” which makes them somewhat blind to issues that are strictly data-based, in particular the management of training data, the need for re-training of models, and concerns of model transparency and explainability.
As organizations move their AI projects out of the lab and into production across multiple business units and functions, the processes by which models are created, operationalized, managed, governed, and versioned need to be made as reliable and predictable as the processes by which traditional application development is managed. In addition, as the markets for AI shift from those relatively few organizations that have the technical expertise required to build models from scratch to those enterprises and organizations looking to consume models built by others, the focus shifts from tooling and platforms focused solely on model development to tools and platforms focused on the overall usage, consumption, and management of models.
Implementing artificial intelligence solutions at scale can be challenging. Many organizations and public sector agencies struggle to rapidly deploy, manage and secure the machine learning models that power the core of today’s AI solutions. Furthermore, data scientists, IT operations, data engineering, line of business, and ML engineering teams often work in silos. This results in complexities for creating, managing, and deploying ML models within their own division or organization. These challenges are further complicated as these organizations share those models within or across the entire organization or agency, or alternatively consume third-party models or models from outside the organization. As a result, the increased complexity of dealing with multiple models in different versions from multiple sources result in issues around model versioning, governance of models and access, potential security risks, challenges with regard to monitoring model usage, and duplicated efforts with multiple teams creating very similar models.
While much of the attention up until now has been focused on the development of machine learning models, as the industry moves from innovators and early adopters to the early majority, later entrants will be more concerned about consuming models developed by others and adoption of recognized best practices rather than building their own models from scratch. This means that these model consumers will be primarily concerned with the quality and reliability of existing models more so than attempting to create a data science organization and investing in tools, technology and people to build their own models.
Thank you for reading this post, don't forget to subscribe to our AI NAVIGATOR!
Simply training machine learning models isn’t sufficient to provide required capabilities. Once a model has been trained, it needs to be applied to a particular problem, but you can apply that model in any of a number of ways. The model can sit on a desktop machine providing results on demand, or it can sit on the edge in a mobile device, or it can sit in a cloud or server environment providing results to a wide range of use cases. Each one of these places where the model is being placed into a real-world situation can be considered a separate deployment, so simply saying the model is deployed doesn’t give us enough information. Putting machine learning models into real-world environments where they are acting on real-world data and providing real-world predictions (i.e. inferencing) is called “operationalizing” the machine learning models. […]
Read more – www.forbes.com
Share this: