Machine learning has proven to be very efficient at classifying images and other unstructured data, a task that is very difficult to handle with classic rule-based software.
Copyright by www.bdtechtalks.com

But before machine learning models can perform classification tasks, they need to be trained on a lot of annotated examples. Data annotation is a slow and manual process that requires humans reviewing training examples one by one and giving them their right label.
In fact, data annotation is such a vital part of machine learning that the growing popularity of the technology has given rise to a huge market for labeled data. From Amazon’s Mechanical Turk to startups such as LabelBox, ScaleAI, and Samasource, there are dozens of platforms and companies whose job is to annotate data to train machine learning systems.
Fortunately, for some classification tasks, you don’t need to label all your training examples. Instead, you can use semi-supervised learning, a machine learning technique that can automate the data-labeling process with a bit of help.
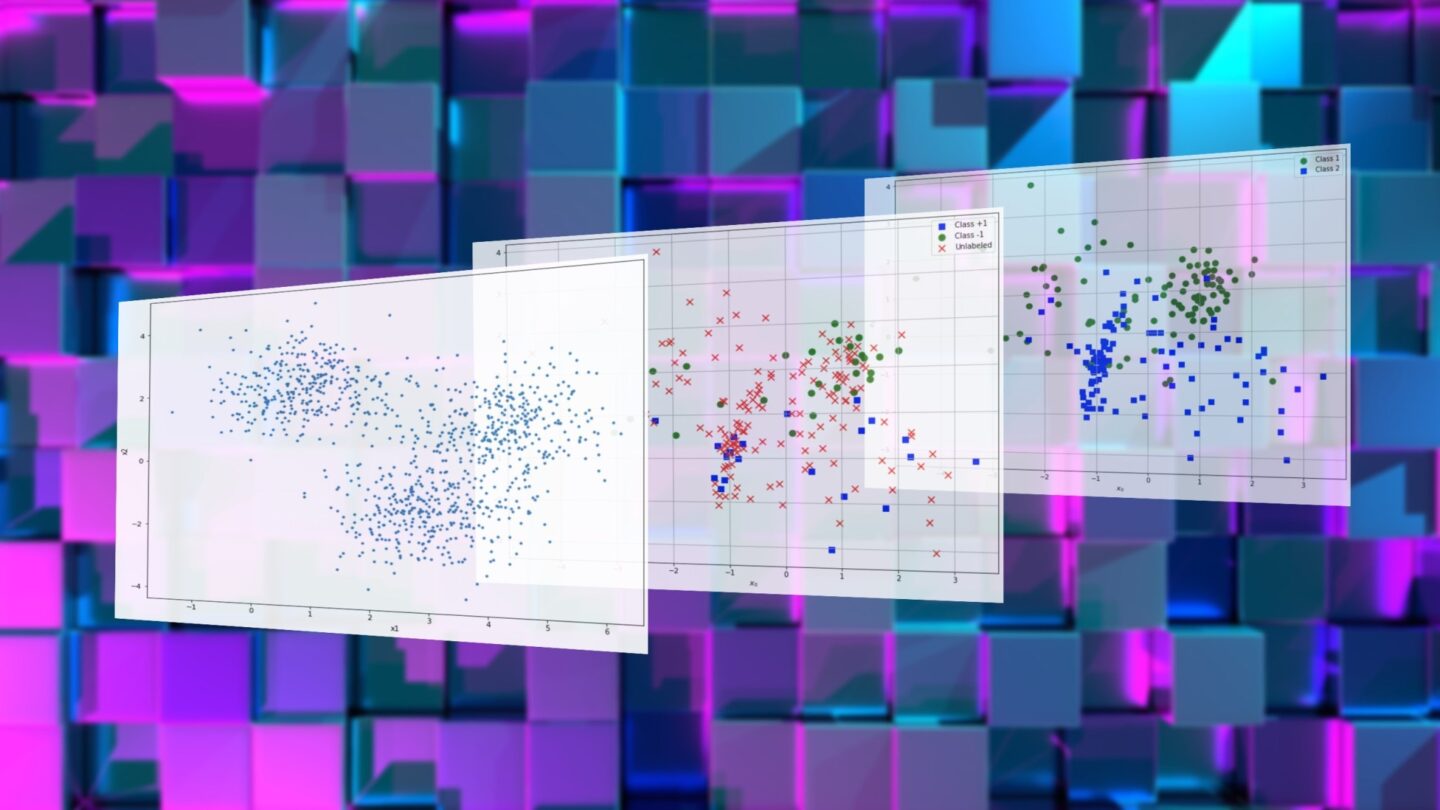
Supervised vs unsupervised vs semi-supervised machine learning
You only need labeled examples for supervised machine learning tasks, where you must specify the ground truth for your AI model during training. Examples of supervised learning tasks include image classification, facial recognition, sales forecasting, customer churn prediction, and spam detection.
Unsupervised learning, on the other hand, deals with situations where you don’t know the ground truth and want to use machine learning models to find relevant patterns. Examples of unsupervised learning include customer segmentation, anomaly detection in network traffic, and content recommendation.
Semi-supervised learning stands somewhere between the two. It solves classification problems, which means you’ll ultimately need a supervised learning algorithm for the task. But at the same time, you want to train your model without labeling every single training example, for which you’ll get help from unsupervised machine learning techniques. […]
Thank you for reading this post, don't forget to subscribe to our AI NAVIGATOR!
Read more: bdtechtalks.com









Machine learning has proven to be very efficient at classifying images and other unstructured data, a task that is very difficult to handle with classic rule-based software.
Copyright by www.bdtechtalks.com
But before machine learning models can perform classification tasks, they need to be trained on a lot of annotated examples. Data annotation is a slow and manual process that requires humans reviewing training examples one by one and giving them their right label.
In fact, data annotation is such a vital part of machine learning that the growing popularity of the technology has given rise to a huge market for labeled data. From Amazon’s Mechanical Turk to startups such as LabelBox, ScaleAI, and Samasource, there are dozens of platforms and companies whose job is to annotate data to train machine learning systems.
Fortunately, for some classification tasks, you don’t need to label all your training examples. Instead, you can use semi-supervised learning, a machine learning technique that can automate the data-labeling process with a bit of help.
Supervised vs unsupervised vs semi-supervised machine learning
You only need labeled examples for supervised machine learning tasks, where you must specify the ground truth for your AI model during training. Examples of supervised learning tasks include image classification, facial recognition, sales forecasting, customer churn prediction, and spam detection.
Unsupervised learning, on the other hand, deals with situations where you don’t know the ground truth and want to use machine learning models to find relevant patterns. Examples of unsupervised learning include customer segmentation, anomaly detection in network traffic, and content recommendation.
Semi-supervised learning stands somewhere between the two. It solves classification problems, which means you’ll ultimately need a supervised learning algorithm for the task. But at the same time, you want to train your model without labeling every single training example, for which you’ll get help from unsupervised machine learning techniques. […]
Thank you for reading this post, don't forget to subscribe to our AI NAVIGATOR!
Read more: bdtechtalks.com
Share this: