Humanity is confronted daily with artificial intelligence (AI), but it is still a challenge to find common ground. Through the adoption of the term intelligence, AI has taken on a variety of problems in the history of psychological intelligence research.
Copyright by Marisa Tschopp & Marc Ruef
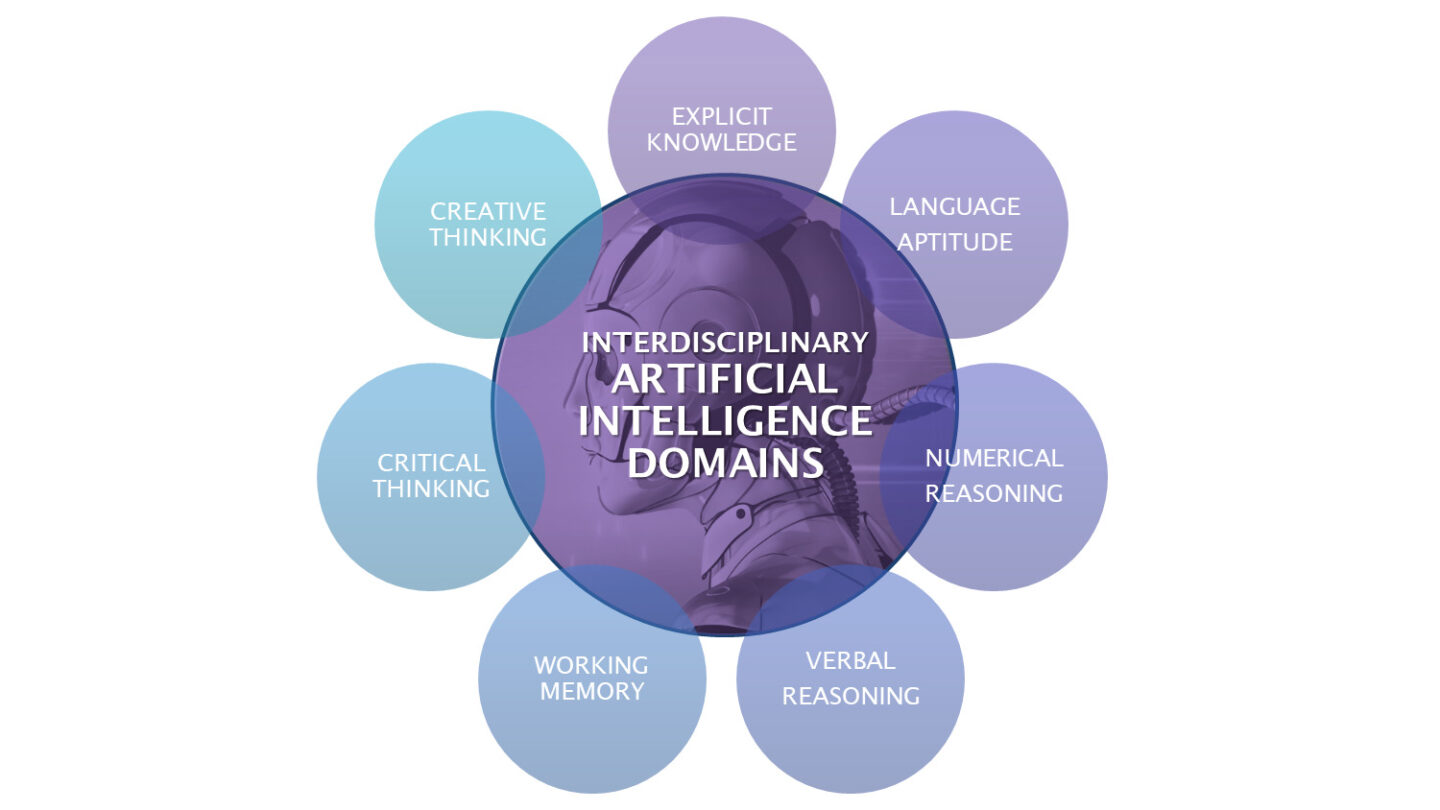
 AI research inevitably requires an interdisciplinary approach. This research project aims to understand, measure, compare, and track changes in the capabilities of conversational AI. From this, an interdisciplinary Artificial Intelligence model was derived: Interdisciplinary Artificial Intelligence Domains, which are understood as a system of problem-solving abilities. It integrates seven categories: Explicit Knowledge, Language Aptitude, Numerical and Verbal Thinking, Working Memory, Critical and Creative Thinking. Furthermore, information processing is subdivided into the forms of thinking following Bloom’s Taxonomy. The Interdisciplinary Artificial Intelligence Quotient Scale (iAIQs Scale) is derived, which reflects academic IQ testing procedures. The evaluation takes place through a multi-level system of response categories and individual weighting. A Key Performance Indicator (KPI) and the A-IQ (Artificial Intelligence Quotient) are the results. The A-IQ tests are performed with conversational AI within their ecosystems: Google Now, Siri (Apple), Cortana (Microsoft) and Alexa (Amazon). The results indicate Siri’s best overall performance due to the strong working memory capabilities, Cortana leads Explicit Knowledge, among others, at the category level, none show critical (except Alexa in part) or creative thinking skills. A solution to automate A-IQ testing is proposed. Limitations and implications for future research and practice are discussed.
AI research inevitably requires an interdisciplinary approach. This research project aims to understand, measure, compare, and track changes in the capabilities of conversational AI. From this, an interdisciplinary Artificial Intelligence model was derived: Interdisciplinary Artificial Intelligence Domains, which are understood as a system of problem-solving abilities. It integrates seven categories: Explicit Knowledge, Language Aptitude, Numerical and Verbal Thinking, Working Memory, Critical and Creative Thinking. Furthermore, information processing is subdivided into the forms of thinking following Bloom’s Taxonomy. The Interdisciplinary Artificial Intelligence Quotient Scale (iAIQs Scale) is derived, which reflects academic IQ testing procedures. The evaluation takes place through a multi-level system of response categories and individual weighting. A Key Performance Indicator (KPI) and the A-IQ (Artificial Intelligence Quotient) are the results. The A-IQ tests are performed with conversational AI within their ecosystems: Google Now, Siri (Apple), Cortana (Microsoft) and Alexa (Amazon). The results indicate Siri’s best overall performance due to the strong working memory capabilities, Cortana leads Explicit Knowledge, among others, at the category level, none show critical (except Alexa in part) or creative thinking skills. A solution to automate A-IQ testing is proposed. Limitations and implications for future research and practice are discussed.
The interest in artificial intelligence seems to be interminable. According to the 2017 AI Index Report (based on the Stanford 100-year Study on AI), over fifteen thousand papers across disciplines have been published in academia only. In addition, an innumerable corpus of articles online and in print add up to the massive spread of information about AI – from rock-solid science to trivial or superficial news, that simply wants to cause a sensation (Stone, 2016).While more people than ever are now confronted with artificial intelligence (intentionally or not), it is still hard to find a common ground of understanding of the concept. The complexity lies within the term itself by adopting the word intelligence as technical, procedural capabilities of machines. It has inherited a myriad of challenges from the long history of psychological intelligence research. From methodological problems (validity, reliability, etc.) to serious allegations of racial sorting by IQ Tests during the Nazi period (Zimbardo, Gerrig & Graf, 2008).
In the present report, the topic of intelligence of man and machine will be approached from different perspectives.
2.1. Defining conversational Artificial Intelligence
According to Russel and Norvig (2012), four main categories of defining artificial intelligence have evolved: (1) Human thinking and (2) behavior, (3) rational thinking and (4) acting. Ray Kurzweil defines it as “the art of creating machines that perform functions that, when performed by humans, require intelligence” (Russel & Norvig, 2012, p. 23). The processing of natural language, providing the opportunity to engage in human conversation which requires intelligence, is part of the category (2) human behavior. With regards to the scope of this paper, it is unnecessary to lean to deep into a philosophical discussion.
A major problem is the lack of definitions of speech operated systems and various names or labels which have been used, which complicates systematic literature search. Nouns to describe these systems are assistant, agent, AI, or the suffix -bot (referred to as a chatbot), extended by one to three adjectives such as intelligent, virtual, voice, mobile, digital, conversational, personal, or chat depending on the context. The variety of names and lack of definitions complicates research and comparability, especially when it comes to evaluation (Jian, 2015; Weston, 2015). It is assumed here that voice-controlled conversational AIs such as Siri or Alexa are classified as socalled weak AI systems and assigned to the field of Natural Language Understanding and Natural Language Processing (Russel & Norvig, 2012). For a detailed further discussion of the definition of artificial intelligence beyond the nomenclature of Conversational AI, see Bryson (2019) and Wang (2019).
2.2. Related Research
According to Hernandez-Orallo (2016), evaluation is the basis of all progress. Hence, it is a critical part for AI research and practice to not only evaluate their products and methods but further to discuss and compare evaluation practices per se.
Thank you for reading this post, don't forget to subscribe to our AI NAVIGATOR!
Researchers, professionals, and others have undertaken attempts to measure and compare conversational AIs, predominantly with conversational AIs like for example Siri (as a part of Apple’s operating system) or Google Now (developed by Google) or also general search engines. Such tests have various perspectives. Between or within conversational AIs, between humans and conversational AIs comparing artificial with human intelligence. […]
Read more – www.researchgate.net









Humanity is confronted daily with artificial intelligence (AI), but it is still a challenge to find common ground. Through the adoption of the term intelligence, AI has taken on a variety of problems in the history of psychological intelligence research.
Copyright by Marisa Tschopp & Marc Ruef
The interest in artificial intelligence seems to be interminable. According to the 2017 AI Index Report (based on the Stanford 100-year Study on AI), over fifteen thousand papers across disciplines have been published in academia only. In addition, an innumerable corpus of articles online and in print add up to the massive spread of information about AI – from rock-solid science to trivial or superficial news, that simply wants to cause a sensation (Stone, 2016).While more people than ever are now confronted with artificial intelligence (intentionally or not), it is still hard to find a common ground of understanding of the concept. The complexity lies within the term itself by adopting the word intelligence as technical, procedural capabilities of machines. It has inherited a myriad of challenges from the long history of psychological intelligence research. From methodological problems (validity, reliability, etc.) to serious allegations of racial sorting by IQ Tests during the Nazi period (Zimbardo, Gerrig & Graf, 2008).
In the present report, the topic of intelligence of man and machine will be approached from different perspectives.
2.1. Defining conversational Artificial Intelligence
According to Russel and Norvig (2012), four main categories of defining artificial intelligence have evolved: (1) Human thinking and (2) behavior, (3) rational thinking and (4) acting. Ray Kurzweil defines it as “the art of creating machines that perform functions that, when performed by humans, require intelligence” (Russel & Norvig, 2012, p. 23). The processing of natural language, providing the opportunity to engage in human conversation which requires intelligence, is part of the category (2) human behavior. With regards to the scope of this paper, it is unnecessary to lean to deep into a philosophical discussion.
A major problem is the lack of definitions of speech operated systems and various names or labels which have been used, which complicates systematic literature search. Nouns to describe these systems are assistant, agent, AI, or the suffix -bot (referred to as a chatbot), extended by one to three adjectives such as intelligent, virtual, voice, mobile, digital, conversational, personal, or chat depending on the context. The variety of names and lack of definitions complicates research and comparability, especially when it comes to evaluation (Jian, 2015; Weston, 2015). It is assumed here that voice-controlled conversational AIs such as Siri or Alexa are classified as socalled weak AI systems and assigned to the field of Natural Language Understanding and Natural Language Processing (Russel & Norvig, 2012). For a detailed further discussion of the definition of artificial intelligence beyond the nomenclature of Conversational AI, see Bryson (2019) and Wang (2019).
2.2. Related Research
According to Hernandez-Orallo (2016), evaluation is the basis of all progress. Hence, it is a critical part for AI research and practice to not only evaluate their products and methods but further to discuss and compare evaluation practices per se.
Thank you for reading this post, don't forget to subscribe to our AI NAVIGATOR!
Researchers, professionals, and others have undertaken attempts to measure and compare conversational AIs, predominantly with conversational AIs like for example Siri (as a part of Apple’s operating system) or Google Now (developed by Google) or also general search engines. Such tests have various perspectives. Between or within conversational AIs, between humans and conversational AIs comparing artificial with human intelligence. […]
Read more – www.researchgate.net
Share this: