Researchers combine artificial intelligence, crowdsourcing and supercomputers to develop better, and more reasoned, information extraction and classification methods WordNet is a lexical database for the English language.
copyright by www.tacc.utexas.edu
 It groups English words into sets of synonyms called synsets, provides short definitions and usage examples, and records a number of relations among these synonym sets or their members. Researchers from The University of Texas at Austin developed a method to incorporate information from WordNet into informational retrieval systems. How do search engines generate lists of relevant links? The outcome is the result of two powerful forces in the evolution of information retrieval: artificial intelligence — especially natural language processing — and crowdsourcing.
It groups English words into sets of synonyms called synsets, provides short definitions and usage examples, and records a number of relations among these synonym sets or their members. Researchers from The University of Texas at Austin developed a method to incorporate information from WordNet into informational retrieval systems. How do search engines generate lists of relevant links? The outcome is the result of two powerful forces in the evolution of information retrieval: artificial intelligence — especially natural language processing — and crowdsourcing.
Determine Relationships between Words
Computer algorithms interpret the relationship between the words we type and the vast number of possible web pages based on the frequency of linguistic connections in the billions of texts on which the system has been trained. But that is not the only source of information. The semantic relationships get strengthened by professional annotators who hand-tune results — and the algorithms that generate them — for topics of importance, and by web searchers (us) who, in our clicks, tell the algorithms which connections are the best ones.
Understanding Language
Despite the incredible, world-changing success of this model, it has its flaws. Search engine results are often not as “smart” as we’d like them to be, lacking a true understanding of language and human logic. Beyond that, they sometimes replicate and deepen the biases embedded in our searches, rather than bringing us new information or insight. Matthew Lease, an associate professor in the School of Information at The University of Texas at Austin (UT Austin), believes there may be better ways to harness the dual power of computers and human minds to create more intelligent information retrieval (IR) systems. […]
read more – copyright by www.tacc.utexas.edu
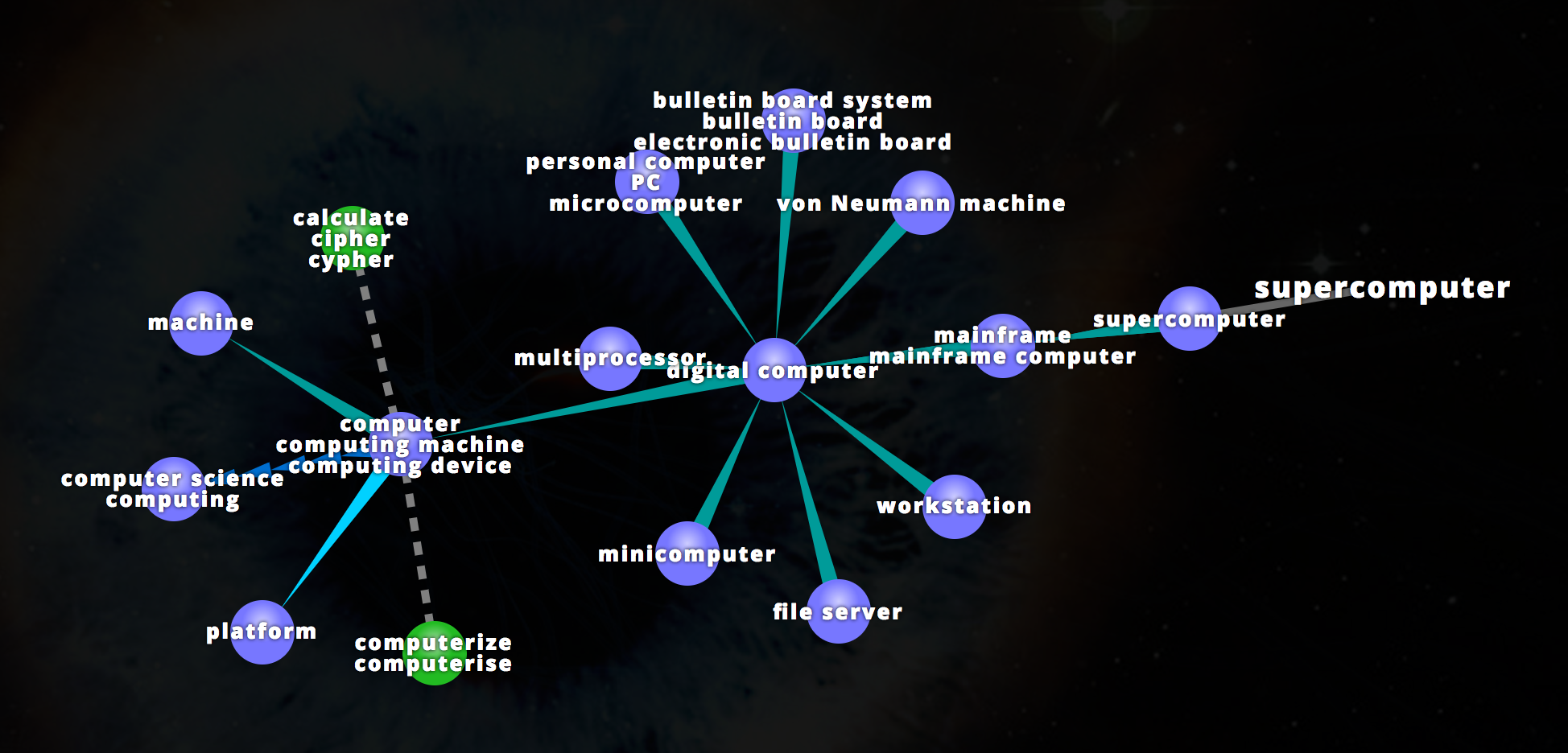









Researchers combine artificial intelligence, crowdsourcing and supercomputers to develop better, and more reasoned, information extraction and classification methods WordNet is a lexical database for the English language.
copyright by www.tacc.utexas.edu
Determine Relationships between Words
Computer algorithms interpret the relationship between the words we type and the vast number of possible web pages based on the frequency of linguistic connections in the billions of texts on which the system has been trained. But that is not the only source of information. The semantic relationships get strengthened by professional annotators who hand-tune results — and the algorithms that generate them — for topics of importance, and by web searchers (us) who, in our clicks, tell the algorithms which connections are the best ones.
Understanding Language
Despite the incredible, world-changing success of this model, it has its flaws. Search engine results are often not as “smart” as we’d like them to be, lacking a true understanding of language and human logic. Beyond that, they sometimes replicate and deepen the biases embedded in our searches, rather than bringing us new information or insight. Matthew Lease, an associate professor in the School of Information at The University of Texas at Austin (UT Austin), believes there may be better ways to harness the dual power of computers and human minds to create more intelligent information retrieval (IR) systems. […]
read more – copyright by www.tacc.utexas.edu
Share this: